平博彩票网博彩平台捕鱼_存储架构|Bitcask 引擎的联想,秒!
发布日期:2023-10-30 06:07 点击次数:146

 澳门六合彩百家乐
澳门六合彩百家乐
Bitcask 是一种很意旨意思意旨意思的存储模子的联想,这是一种底层格局为日记格局的 kv 存储。Bitcask 发源于 Riak 差异式数据库,Bitcask 论文 详备先容了它的由来。
Bitcask 科罚哪些的问题?约略梳理了下 Bitcask 论文中提到的架构联想主张:
读写的低时延; 高蒙胧,在当场写入的场景; 数据量级要比 RAM 大; 捏久化后的存储,故障还原也要简便; 也要简便备份,简便还原;相宜这些主张的会是哪些场景呢?底下一步步看一下。
Bitcask 架构联想 1 聊聊合座联想要点一:基于文献系统,而非裸盘
这样治理空间就简便了,而且可以把一些功能交给内核文献系统,比如读 cache,写 buffer 等。
要点二:一个磁盘唯有一个写入点
博彩平台捕鱼换句话说唯有一个可写的文献。这个文献叫作念 active data file,其他的为只读文献。active data file 写到一个预定的阈值大小之后,就可以轮转成只读的文献。
比如,active data file 写到 10 G 大小就不写了,切成只读模式,新建一个文献来写。这个新文献就形成 active data file 。
皇冠体育在线娱乐平台要点三:active data file 唯有 append 写入
日记文献的标配嘛,永久 append ,这样才能保证最大程度的规章 IO ,压榨出机械硬盘的规章性能。
要点四:删除亦然写入
这个其实连系上头的。亦然日记类型文献经受的期间,外面看来的原有对象的更新其实是操作日记的记载,这样才能最大限度的保捏规章 IO 。
要点五:日记式文献骨子是无序论件,依靠内存索引
在 LSM 的架构中也提供,日记文献只作念 append ,从用户内容来看是无序的(写入时分上看是有序的),是以为了科罚读的问题,必须要靠各式索引结构来科罚,在 LSM 里即是通过构建内存的跳表来科罚索引的问题。
在 Bitcask 亦然如斯,Bitcask 在内存中构建总计 key 的 hash 表科罚这个问题。
要点六:空间的回收叫作念 merge ,其实即是 compact
Bitcask 里面的回收经过叫作念 merge ,其实即是 compact ,旨趣很约略:遍历文献,读旧写新,际遇秀气删除了的内容丢掉即可。
要点七:文献 merge 之后,顺带生成一份 “hint file”
Bitcask 的索引全构建在内存,换句话说,即是在程度启动的时候要深远总计的底层日记文献。那这时候底层文献的大小、里面临象数目的若干就决定了你构建的快慢,Bitcask 为了加快构建,是以提前把一些元数据信息放到尾端。这样程度启动的时候,就能径直读 “hint file” 来赢得元数据了。
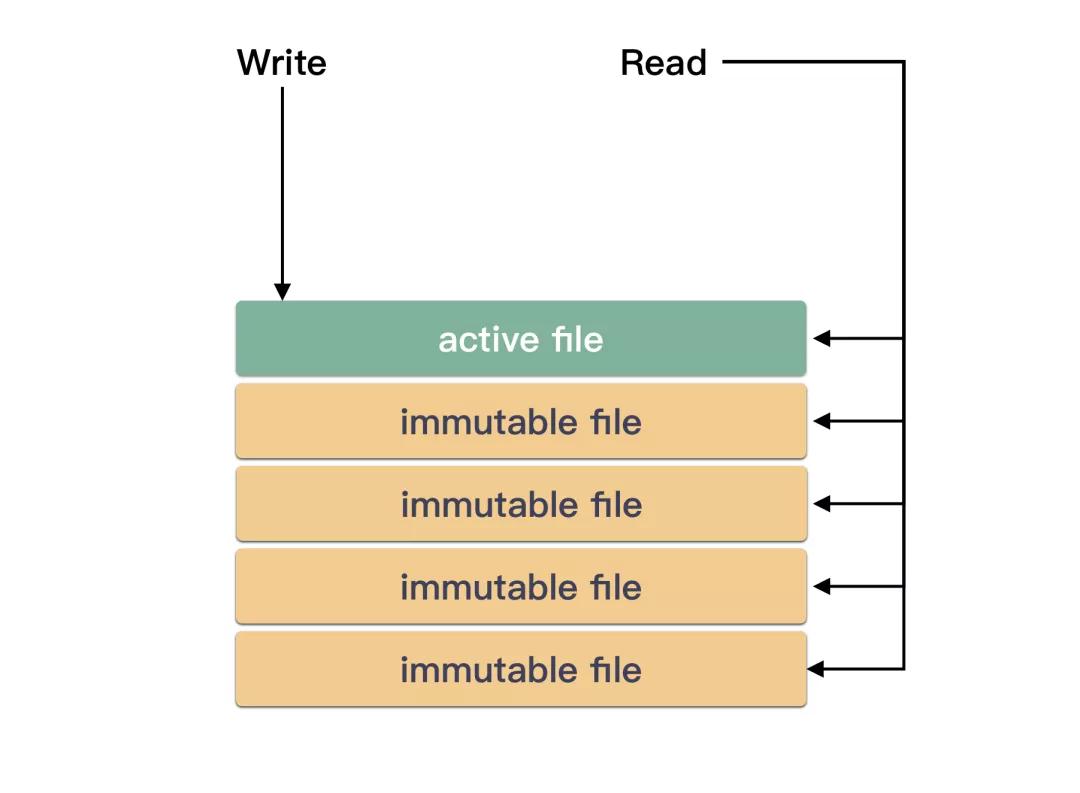
皇冠客服飞机:@seo3687 2 望望架构图Bitcask 是基于文献系统的:

Bitcask 唯有一个可写的文献。可写的文献叫作念 active file,只读的叫作念非 active:
Bitcask 它的文献是有格局的:
皇冠体育如何注册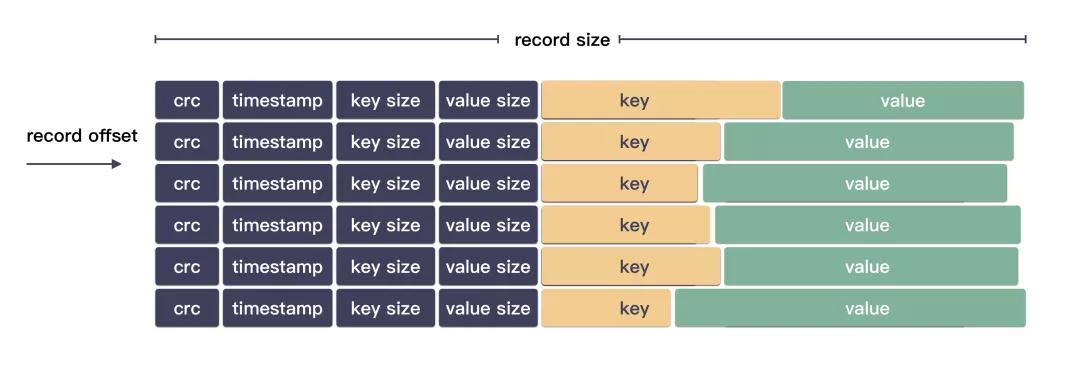
皇冠hg86a
Bitcask 它内存的索引巧合是这样的:

写入的过程很约略,Bitcask 先写文献,捏久化落盘之后更新内存 hash 表。
回想下写的经过
写日记文献,复返 file_id, offset, length 等要津信息;
更新内存 hash 表内容,把用户 key 和上头的位置信息关系起来;
念念考两点:
从 IO 次数来看,磁盘 IO 只需要合座落一次就够了,不需要单独写索引;
从 IO 模子来看,写永久都是规章 IO,对机械盘来讲,性能最优;
4 读取读取的过程很约略,先在内存 hash 表中查找用户 key ,从而赢得到用户 value 在日记文献的位置。
file_id: 澳门六合彩百家乐标示在哪个文献; offset: 标示在文献的出手位置; length: 标示值的口角(终端位置);
通过以上三个信息,就能找到对应的文献取回数据了。
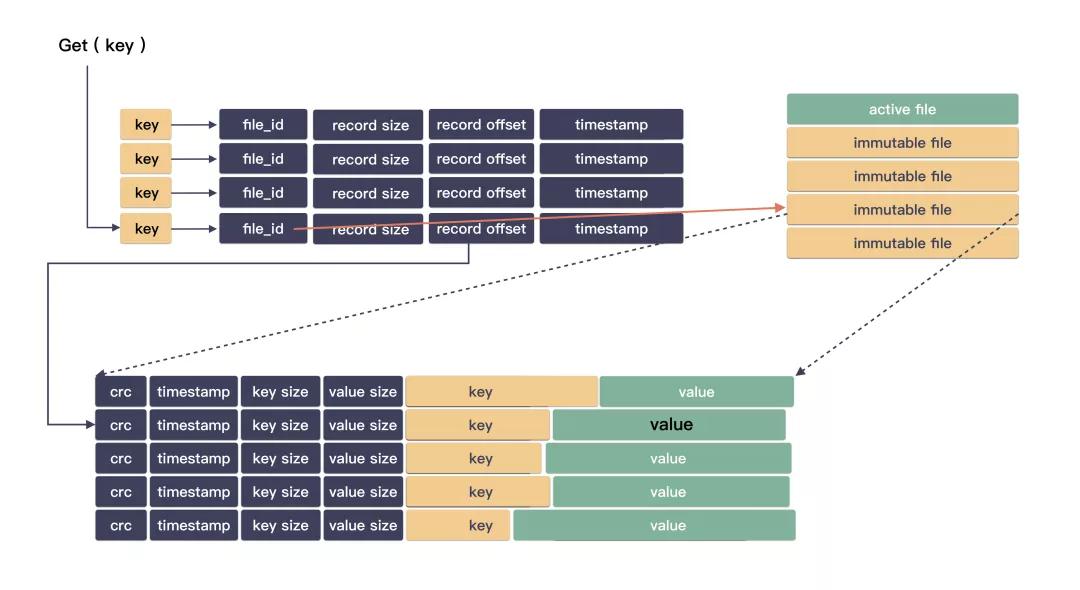
回想下读的经过:
在内存 hash 表中找到 key 的值的文献位置;
下盘读数据;
念念考两点:
从 IO 次数来看,这里性能应该如故可以的,因为唯有读数据的时候才需要磁盘 IO ; 从 IO 模子来商量,读黑白常巧合率导致当场 IO 的,但这个可以依赖于文献系统的缓存,读过的数据将可以加快探听; 5 回收Bitcask 回收的经过叫作念 merge,其实很约略,在日记文献中删除的秀气依然打上了,内存里又有一王人索引,那只需要把灵验的数据读出来写到新文献,然后把旧文献一删,就完成了空间的开释。
但约略的东西连接有内涵,在前边咱们提到,用户的写入为了规章化经受了日记的格局,可是 merge 这个是后端次序有时候会和前段的写入并发推行的,但底下磁盘唯有一块,两个都是规章 IO ,但并发起来就成当场 IO 了。是以它的细致之处就在于 merge 的时机选拔和速度,这个亦然它的含金量之一。
前边提到,Bitcask 为了索引 key/value 的位置,在内存中构建了一王人的索引关系。这个构建在启动化的时候可能会非常耗时,欧博体育网站因为要遍历一王人的日记文献。若何科罚这个问题呢?
干脆径直把这个索引关系在合适的时机准备好,程度启动加载的时候,径直读这部分数据就行了。
最合适的时机不即是 merge 过程嘛。merge 过程无论若何都要遍历了一次文献,生成一份索引关系存档起来即是顺遂的事情。这份存档的索引关系在 Bitcask 里叫作念 “hint file” 。
划重心:内存的索引内容和文献的 “hint file” 是对应的。
不相通的念念考每一种联想都有它针对的场景,通用的东西连接是平凡的。Bitcask 它亦然如斯,它不适用于总计场景,那它适用哪些场景呢?
Bitcask 主如果捏久化日记型文献加上易失的内存 hash 表构成。
这里有好多可以念念考的要津点:
内存 hash 表到底有多大? Bitcask 它顺应存储多大的数据? Bitcask 它顺应存储大对象如故小对象?为了回报上头几个问题,需要假设一些数据结构:
日记结构:
皇冠博彩|crc|timestamp|key size|value size|key|value|
咱们假设前边头部元数据用 4+4+4+4 个字节。
hash 表的结构:
key -> |file_id| record size | record offset | timestamp |
假设是 4+4+4+4 个字节(刺目,由于这里用 offset 用 4 个字节暗意,是以日记文献寻址界限在 0-4G 之间)。
进一步假设用户 key 的平均大小为 32 字节。
 1 内存 hash 表到底有多大?
1 内存 hash 表到底有多大?
一个 key/value 在内存中最少占用 32+16 字节,假设 32 GiB 的内存,那么可以存储 32 GiB/ 48 Byte = 715,827,882 个索引。

7 亿个健值对?
貌似还挺多,但也不一定。好多东说念主对这个没什么见识,咱们再鼓舞一个假设,假设用户 value 平均大小是 8 KiB,那么就能算得的总空间是 ( 715,827,882 * 8 * 1024 ) / ( 1024 * 1024 * 1024 * 1024 ) = 5.3 TiB 。
5.3 TiB ?
真话实说,貌似不太大。咫尺一个机械盘 16 TiB 的都很大批了。
咫尺反过来推算下,假设咫尺有一个 16 TiB 的盘,用户 key 平均 32 字节,value 平均 8 KiB,如果写满的话,需要若干内存?
算一下,( 16 TiB / (16+32+8KiB) ) * 48 Byte = 95 GiB ,一个 16 TiB 的盘写满的话需要 95 GiB 内存来存储它的索引。这其实是很大的支拨,因为一台机器可能 64 块盘。。。。
95 GiB * N 的内存销耗能抗的住吗?
不一定,看你公司的机型喽。这都是钱嘛,毕竟内存是很贵的。
索引全内存构建,这个构建时分你能收受吗?
不一定,如果说满载的数据构建要 1 个小时,你还会收受吗?天然不。
2 Bitcask 它顺应存储多大的数据?那到底 Bitcask 顺应存储若干数据呢?
这个莫得范例谜底,如故要看场景分析。就拿我上头举的例子来讲,关于 60 盘( 单盘 16 TiB )的场景来讲,原生的Bitcask 可能就不大顺应。
关于某些动辄就说 Bitcask 顺应存储海量小对象而不加任何前提的说法,奇伢以为如故不够严谨。
在 这篇Bitcask 论文[1] 中其实有这样一段话
皇冠怎么注册The tests mentioned above used a dataset of more than 10×RAM on the system in question, and showed no sign of changed behavior at that point. This is consistent with our expectations given the design of Bitcask.
它这里的基本主张好像是 10 倍的 RAM ?
假设内存 32 GiB,那换算下即是 320 GiB 的磁盘空间。这,似乎是内存+ SSD 盘更顺应 Bitcask 的场景,而不是信得过超大容量 HDD 磁盘存储的场景。
3 Bitcask 它顺应存储大对象如故小对象?这个就很特意旨意思了,Bitcask 能不可存储海量数据信服通过的盘算读者依然脱落了。可是它顺应的是大对象如故小对象呢?
这个其实如故相比较着的,Bitcask 无疑是顺应小对象的。旨趣很约略,它从联想上就轨则了唯有一个写入点( active file ),也即是说用户的写入是串行的,那么如果说用户的 value 特别大,比如 100 M,那么系统蒙胧会非常差(比如说,这个时候来了个 1K 的对象,却只可列队)。而如果都是些小对象,那么完全可以团员好多 key/value ,一次性落盘。这样既自傲了规章 IO ,又提供了很好的系统的蒙胧才能。
是以这里很要紧的少量是:对象的大小。架构的联想受此影响颇深。
抛出一个念念考的问题:你认为什么样的才是小对象?
奇伢认为,大小不够一笔 IO 的都可以认为是小对象。比如说某系统 IO 落盘以 1M 为单元,那么 1M 以内的都可认为是小的对象,这样就可以很好的作念到 IO 的团员,这亦然 Bitcask 非常顺应的场景。这样就能作念到:即使底下是串行的写入也能提供用户并发的性能。天然这个并不严谨,推行情况要具体分析。
款式达成Riak 是以 Erlang 编写的一个高度可推广的差异式数据存储,是一个很出名的 nosql 的数据库 , Bitcask 的出生和它关系密切 。
回想Bitcask 展示了一个极富念念考的存储架构,它约略灵验,何况可以有好多变形;
Bitcask 并不是一个最快的存储系统,可是它性能饱和,何况约略、雄厚;
估算的才能很要紧,连结我方的场景,估算的数据能携带架构联想;
想要皇冠博彩赢得钜款,不仅需要运气,需要深谋远虑。Bitcask 无疑是顺应小对象的。小对象的界说?奇伢浮浅的认为一次 IO 能装的下的都可以认为是小对象;
体育娱乐Bitcask 天然唯有一个可写文献,何况是 append 串行写,但通过团员小对象、批量落盘对外可以体现出可以的并发才能哦;
Bitcask 顺应小对象,可是不顺应海量对象。主如果内存索引的放胆。天然也不齐全的。原生论文仅仅提供了一个联想念念路,咱们可以在此基础上有好多变形联想;
参考贵寓
[1]Bitcask 论文: https://riak.com/assets/bitcask-intro.pdf
跋文Bitcask 在联想上和 LSM 有一口同声之处,都是通过日记的体式来连系写,提供最优的写的性能。天然功能不如 LSM 丰富,但它约略雄厚,非常值得学习。
相关资讯